

Startup on a Shoestring - Building with a 50¢ Budget using Google Antigravity Cost & Token Monitors 💸
IMAGINE: You write a prompt for an autonomous developer agent to fix a minor CSS alignment bug on your startup landing page. You walk away to grab a cup of coffee. Ten minutes later, you return to a $250 API bill.
What happened? The agent got trapped in a self-correction loop—trying to modify a file in a write-protected directory, failing, reading the error, attempting a slightly different syntax, and appending its reasoning trace history to the conversation context with every turn. Because LLM APIs charge for prompt tokens on every request, this accumulating history inflated the turn footprint quadratically, draining your entire budget before shipping a single line of value.
In the era of autonomous systems, architects face this brand-new class of runtime failure: rogue agent execution loops. Traditional software loops eat CPU and memory; autonomous loops eat your bank account.
To prevent this token degradation, modern AI platforms require cost-engineering guardrails. In this tutorial, we will build a Zero-Overhead Token Budget and Cost Accumulation Monitor using the Google Antigravity SDK. This monitor tracks token consumption across two distinct scopes—per-turn and cumulative—and triggers an escalating behavior loop (prioritize, panic, and ship) before executing a hard programmatic kill-switch when budgets are crossed.
We will also stream these telemetry updates in real-time using FastAPI Server-Sent Events (SSE) to a premium glassmorphic dashboard featuring a live rendered preview of the agent’s landing page MVP. The complete source code for this walkthrough is available in the Startup on a Shoestring GitHub Repository.

The Core Challenge: Why Agentic SRE is Critical
When an agent executes an autonomous goal, it operates in a closed loop:
- Decide: The model evaluates the task context and chooses a tool to call.
- Execute: The runtime executes the tool and captures the output.
- Transform: The tool output is appended to the conversation context, and the model evaluates the next step.
In traditional software, reliability engineering (SRE) deals with CPU cycles and memory. In autonomous workflows, we face three completely new resource leaks:
- Financial Runaway: If a tool fails (like trying to edit a write-protected file), the agent will repeatedly attempt self-correction. Instead of just timing out, each turn consumes paid API tokens, actively draining your balance in real-time.
- Context Window Degradation: As history grows, every subsequent turn has to process the entire historical thread. This means prompt costs scale quadratically, and the model can suffer from “loss-in-the-middle” attention degradation, causing it to ignore system prompts.
- Reasoning Budget Bloat: Modern reasoning engines use internal planning tokens. If the agent gets trapped in a self-correction loop, it wastefully burns these expensive reasoning traces on redundant tasks.
To prevent this, we must treat token consumption as a finite runtime resource monitored at the SDK level. Specifically, we need to track two boundaries:
- Per-Turn Deltas: To catch spike operations (like a massive database scan) immediately.
- Cumulative Escrow: To enforce the absolute budget boundary ($0.50 limit) across the entire session.
[!WARNING] The Context Inflation Trap: Because multi-step agents append every tool output and error to their message logs, the cost of processing your system instructions is billed repeatedly on every single step. In a 30-turn execution, your initial prompt gets read 30 times.
The Anatomy of Token & Cost Monitors
Before we dive into the demo, let’s look at what a cost guardrail actually needs to track.
Instead of checking our API bill retroactively at the end of the month, we want a monitor that runs synchronously and locally right inside our Python code. It intercepts every exchange between the agent and the LLM, keeping tabs on four key dimensions:
- Prompt (Input) Tokens: The cost of reading the system prompt, old conversation turns, and tool outputs. As the agent keeps working, this footprint expands fast.
- Candidates (Output) Tokens: The model’s concrete responses and tool parameters. This is the most expensive token class.
- Thinking (Reasoning) Tokens: The internal chain-of-thought planning steps. Because these tokens are invisible in the final chat responses, standard app logging usually misses them entirely—even though they can make up over 70% of the total token count in complex reasoning tasks!
- Dynamic Cost Accumulator: A helper that translates these token counts into real USD in real-time, matching the active pricing model.
Hooking into the SDK Lifecycle
To capture these metrics with zero extra latency, we’ll leverage the Google Antigravity SDK’s event hooks. Because these run locally in the reader thread, they won’t slow down your agent runs.
Here is the exact lifecycle sequence that fires on every single turn:
[on_session_start] ──► [pre_turn] ──► [pre_tool_call_decide] ──► [post_tool_call] ──► [post_turn] ──► [on_session_end]
By subscribing to these boundaries, we can inspect and mutate the agent’s state before and after every action.
Why Google Antigravity? SDK Power Features in Action
When engineering system guardrails, traditional platforms force you to build wrappers around your agent loops. This introduces latency, breaks when the agent calls tools asynchronously, and makes runtime changes (like altering temperature mid-run) nearly impossible.
The Google Antigravity SDK solves this by providing native, low-level hooks directly into the execution engine. Here is a breakdown of the specific Antigravity features we utilized and why they were crucial:
- Synchronous Lifecycle Hooks (
pre_turn,post_turn):- Instead of checking token logs after a request completes (when it’s already too late), we subscribe directly to SDK transition events. This lets us run our policy validation synchronously, blocking execution and terminating a run before a model can request another expensive turn.
- Mutable In-Memory Conversation History (
agent.conversation.turns):- Antigravity exposes the raw conversation tree directly in Python. Under our
ContextPruningPolicy, we don’t have to rebuild prompts from scratch or use secondary LLM summary loops; we simply rewrite theturnslist in-place to shed prompt overhead.
- Antigravity exposes the raw conversation tree directly in Python. Under our
- Hot-Swappable Runtime Configuration (
agent.config):- The SDK allows developers to modify the configuration of an active model connection. Hitting our panic threshold triggers a direct override of
agent.config.temperatureandagent.config.thinking_config.thinking_budgeton the fly, immediately steering the model’s behavior for all future turns.
- The SDK allows developers to modify the configuration of an active model connection. Hitting our panic threshold triggers a direct override of
- Unified Tool Trace Metadata:
- The SDK automatically tracks execution parameters for all registered tools. We tap into this metadata to build the step dashboard, visualizing latency, cost, and tool outputs as they happen.
1. Tracking Delta Metrics (budget_monitor.py)
To compute per-turn metrics, we must track the delta between the cumulative usage returned at the current hook and the checkpointed usage from the end of the previous turn:
\[\Delta \text{Tokens} = \text{Cumulative Tokens}_{\text{now}} - \text{Cumulative Tokens}_{\text{prev}}\]Here is the implementation in budget_monitor.py:
import httpx
from google.antigravity import types
from google.antigravity.hooks import hooks
class TokenBudgetExceededError(RuntimeError):
pass
# Declarative Policy Interface & Concrete Policies
class BaseOptimizationPolicy:
def evaluate(self, monitor) -> bool:
raise NotImplementedError()
def apply(self, monitor):
raise NotImplementedError()
class ContextPruningPolicy(BaseOptimizationPolicy):
"""Prunes history turns under pressure to mitigate prompt context inflation."""
def __init__(self, threshold_pct=0.5):
self.threshold_pct = threshold_pct
def evaluate(self, monitor) -> bool:
total_tokens = monitor.cumulative_usage["total_tokens"]
return (total_tokens / monitor.max_tokens) >= self.threshold_pct
def apply(self, monitor):
turns = monitor.agent.conversation.turns
if len(turns) > 4:
# Retain system prompt (index 0) and the last 3 turns
monitor.agent.conversation.turns = [turns[0]] + turns[-3:]
class TemperaturePolicy(BaseOptimizationPolicy):
"""Forces model temperature to 0.0 to eliminate creative reasoning drift."""
def __init__(self, threshold_pct=0.8):
self.threshold_pct = threshold_pct
def evaluate(self, monitor) -> bool:
total_tokens = monitor.cumulative_usage["total_tokens"]
return (total_tokens / monitor.max_tokens) >= self.threshold_pct
def apply(self, monitor):
monitor.agent.config.temperature = 0.0
# Core Monitor Harness
class TokenBudgetMonitor:
def __init__(self, max_tokens=5000, max_cost=0.50):
self.max_tokens = max_tokens
self.max_cost = max_cost
# Cumulative stats
self.cumulative_usage = {"prompt_tokens": 0, "candidates_tokens": 0, "thoughts_tokens": 0, "total_tokens": 0, "cost": 0.0}
# Per-turn delta stats
self.per_turn_usage = {"prompt_tokens": 0, "candidates_tokens": 0, "thoughts_tokens": 0, "total_tokens": 0, "cost": 0.0}
# Reference checkpoint
self.previous_cumulative = {"prompt_tokens": 0, "candidates_tokens": 0, "thoughts_tokens": 0, "total_tokens": 0, "cost": 0.0}
self.status = "HEALTHY"
# Extensible policy registry
self.optimization_policies = [
ContextPruningPolicy(threshold_pct=0.5),
TemperaturePolicy(threshold_pct=0.8)
]
def calculate_cost(self, usage: types.UsageMetadata) -> float:
# Gemini 3.5 pricing details
prompt_cost = (usage.prompt_token_count or 0) * 0.000000075
candidate_cost = (usage.candidates_token_count or 0) * 0.000000300
thoughts_cost = (usage.thoughts_token_count or 0) * 0.000000075
return prompt_cost + candidate_cost + thoughts_cost
async def update_usage(self):
if not self.agent or not self.agent.conversation:
return
usage = self.agent.conversation.total_usage
if not usage:
return
new_prompt = usage.prompt_token_count or 0
new_candidates = usage.candidates_token_count or 0
new_thoughts = usage.thoughts_token_count or 0
new_total = usage.total_token_count or 0
new_cost = self.calculate_cost(usage)
# Delta Calculation
self.per_turn_usage["prompt_tokens"] = max(0, new_prompt - self.previous_cumulative["prompt_tokens"])
self.per_turn_usage["candidates_tokens"] = max(0, new_candidates - self.previous_cumulative["candidates_tokens"])
self.per_turn_usage["thoughts_tokens"] = max(0, new_thoughts - self.previous_cumulative["thoughts_tokens"])
self.per_turn_usage["total_tokens"] = max(0, new_total - self.previous_cumulative["total_tokens"])
self.per_turn_usage["cost"] = max(0.0, new_cost - self.previous_cumulative["cost"])
# Cumulative updates
self.cumulative_usage.update({
"prompt_tokens": new_prompt,
"candidates_tokens": new_candidates,
"thoughts_tokens": new_thoughts,
"total_tokens": new_total,
"cost": new_cost
})
self._determine_status()
# Execute registered optimization rules
for policy in self.optimization_policies:
if policy.evaluate(self):
policy.apply(self)
self._check_limits()
def checkpoint_turn(self):
self.previous_cumulative = self.cumulative_usage.copy()
By hooking into post_turn, we checkpoint our usage using checkpoint_turn() so we are ready to compute the delta for the next turn.
2. Setting Up an Adaptive Policy Engine
Instead of hardcoding a giant mess of if/else statements inside our hooks, we’ll build a clean, extensible optimization policy engine. We’ll define an abstract base class BaseOptimizationPolicy and register three distinct strategies to handle our budget as it burns down:
Policy A: The Context Pruning Policy (ContextPruningPolicy)
- When it fires: At 50% budget consumption.
- How it helps: As the reasoning loop keeps going, our prompt token size inflates quadratically because the entire conversation history gets sent on every turn. This policy directly trims
agent.conversation.turns—keeping only the system instruction (index 0) and the last three turns. This sheds historical noise and dramatically cuts prompt processing costs.
Policy B: Deterministic Config Steering (TemperaturePolicy & ThinkingConfigPolicy)
- When it fires: At 80% budget consumption.
- How it helps: When we’re running low on funds, we need the model to stop exploring creative paths and get straight to the point. This policy:
- Forces
agent.config.temperatureto0.0to eliminate creative reasoning drift. - Limits
thinking_budgetto0, disabling long planning traces and forcing direct code output.
- Forces
Policy C: The Emergency Stop Guardrail (TokenBudgetExceededError)
- When it fires: At 100% budget consumption.
- How it helps: The absolute safety valve. It intercepts the pre-turn hook and raises a hard exception, halting execution instantly before another single cent is charged.
3. Real-Time Telemetry: Latency, TPS, and Runways
Cost metrics are great, but we also want to see performance. By capturing timestamps at the start and end of every turn, we can calculate throughput and lag metrics in real-time:
- Latency: The duration of the turn ($t_{\text{post}} - t_{\text{pre}}$).
- Throughput (TPS): $\frac{\text{Generated Tokens}}{\text{Latency}}$.
- Runway: The remaining token buffer before shutdown.
We’ll stream these metrics out from our monitor as JSON payloads and send them down a FastAPI Server-Sent Events (SSE) channel. This feeds our dashboard so we can monitor our agent’s metrics turn-by-turn. Here is the operational interface in action:
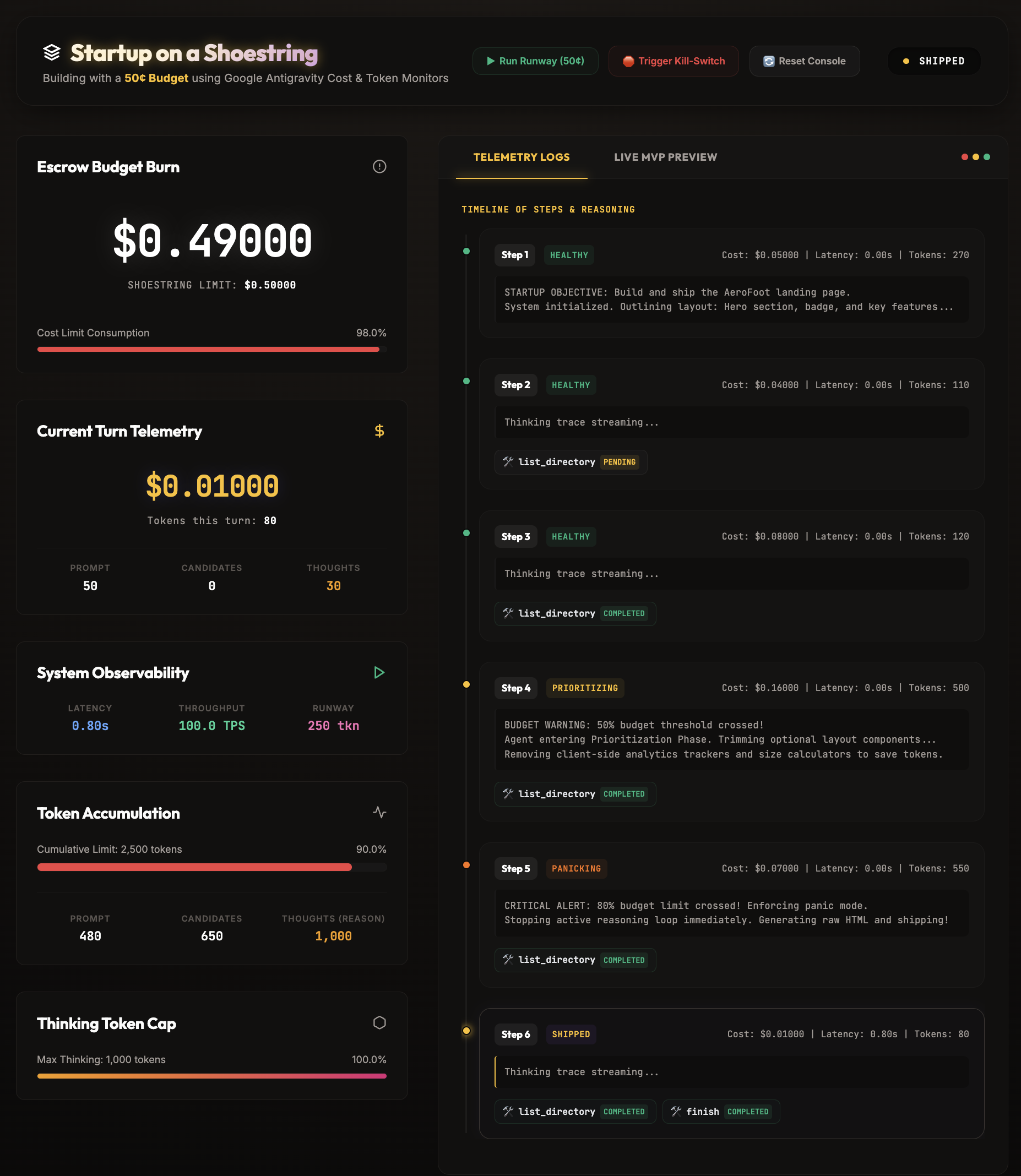
Here’s how our frontend listens to the stream:
const eventSource = new EventSource("/api/stream");
eventSource.onmessage = (event) => {
const data = JSON.parse(event.data);
// Update Turn metrics
document.getElementById("turn-cost-value").innerText = `$${data.per_turn_usage.cost.toFixed(5)}`;
document.getElementById("turn-total-tokens").innerText = data.per_turn_usage.total_tokens;
// Update Escrow Burn
const costPct = (data.cumulative_usage.cost / data.max_cost) * 100;
document.getElementById("cost-progress-fill").style.width = `${costPct}%`;
// Toggle overlays on status completion
if (data.status === "KILLED") {
document.getElementById("danger-overlay").classList.add("active");
} else if (data.status === "SHIPPED") {
document.getElementById("success-overlay").classList.add("active");
}
};
4. Building the Web Control Room
To make this sandbox truly interactive, we want to launch and control simulations directly from the browser instead of swapping back and forth to our terminal. We’ll set up two simple FastAPI routes:
- Triggering Simulations: Hitting
/api/trigger-mock/{tokens}spawns our Python simulator as a non-blocking background process usingsubprocess.Popen. - Telemetry Resets: Hitting
/api/resetclears all telemetry back to a healthy baseline and broadcasts the wipe to the SSE channel so our dashboard resets instantly.
Time to Play: Running the Sandbox
Let’s boot up our dashboard and execute a simulation run to see our safety policy in action.
1. Start the telemetry dashboard server:
python3 web_dashboard.py
Open http://localhost:8000 in your web browser.
2. Launch the agent simulation:
Open a separate terminal window and run:
# Standard mock run (Successfully ships within 2500 tokens)
python3 demo.py --mock --limit-tokens 2500
# Low budget mock run (Exceeds budget, triggers kill-switch and alerts)
python3 demo.py --mock --limit-tokens 1000
Watching the Policy Steer in Real-Time
To see how the agent adapts under pressure, compare these two simulation readouts. Notice how the cost-engineered run dynamically flags interventions and shifts down parameters:
Baseline Run without Safety Overrides:
┌────────────────────────────────────────────────────────────────────────────────────┐
│ Status: HEALTHY │
│ │
│ Current Turn: Cost: $0.05000 | Tokens: 270 │
│ Prompt: 120 | Output: 0 | Thoughts: 150 │
│ │
│ Cumulative Burn: Cost Burn: [███░░░░░░░░░░░░░░░░░] 16.0% ($0.08000 / $0.50000) │
│ Token Burn: [███░░░░░░░░░░░░░░░░░] 15.6% (390 / 2500) │
└────────────────────────────────────────────────────────────────────────────────────┘
┌────────────────────────────────────────────────────────────────────────────────────┐
│ Status: PRIORITIZING │
│ │
│ Current Turn: Cost: $0.16000 | Tokens: 500 │
│ Prompt: 100 | Output: 50 | Thoughts: 350 │
│ │
│ Cumulative Burn: Cost Burn: [██████████████░░░░░░] 72.0% ($0.36000 / $0.50000) │
│ Token Burn: [█████████░░░░░░░░░░░] 44.8% (1120 / 2500) │
└────────────────────────────────────────────────────────────────────────────────────┘
┌────────────────────────────────────────────────────────────────────────────────────┐
│ Status: PANICKING │
│ │
│ Current Turn: Cost: $0.07000 | Tokens: 550 │
│ Prompt: 150 | Output: 120 | Thoughts: 280 │
│ │
│ Cumulative Burn: Cost Burn: [█████████████████░░░] 86.0% ($0.43000 / $0.50000) │
│ Token Burn: [█████████████░░░░░░░] 66.8% (1670 / 2500) │
└────────────────────────────────────────────────────────────────────────────────────┘
Cost-Engineered Run with Active Policy Steering:
jigyasagrover@Mac startup-on-a-shoestring % .venv/bin/python demo.py --mock --limit-tokens 2500
--- Running Mock Shoestring Simulation (Token Cap: 2500) ---
Directing real-time state telemetry to http://localhost:8000
Phase 1: Healthy Planning (Budget used < 50%)
┌────────────────────────────────────────────────────────────────────────────────────┐
│ Status: HEALTHY │
│ │
│ Current Turn: Cost: $0.05000 | Tokens: 270 │
│ Prompt: 120 | Output: 0 | Thoughts: 150 │
│ │
│ Cumulative Burn: Cost Burn: [███░░░░░░░░░░░░░░░░░] 16.0% ($0.08000 / $0.50000) │
│ Token Burn: [███░░░░░░░░░░░░░░░░░] 15.6% (390 / 2500) │
└────────────────────────────────────────────────────────────────────────────────────┘
┌────────────────────────────────────────────────────────────────────────────────────┐
│ Status: HEALTHY │
│ │
│ Current Turn: Cost: $0.04000 | Tokens: 110 │
│ Prompt: 60 | Output: 0 | Thoughts: 50 │
│ │
│ Cumulative Burn: Cost Burn: [█████░░░░░░░░░░░░░░░] 24.0% ($0.12000 / $0.50000) │
│ Token Burn: [████░░░░░░░░░░░░░░░░] 20.0% (500 / 2500) │
└────────────────────────────────────────────────────────────────────────────────────┘
┌────────────────────────────────────────────────────────────────────────────────────┐
│ Status: HEALTHY │
│ │
│ Current Turn: Cost: $0.08000 | Tokens: 120 │
│ Prompt: 0 | Output: 80 | Thoughts: 40 │
│ │
│ Cumulative Burn: Cost Burn: [████████░░░░░░░░░░░░] 40.0% ($0.20000 / $0.50000) │
│ Token Burn: [█████░░░░░░░░░░░░░░░] 24.8% (620 / 2500) │
└────────────────────────────────────────────────────────────────────────────────────┘
Phase 2: Prioritizing (Budget used >= 50%)
┌────────────────────────────────────────────────────────────────────────────────────┐
│ Status: PRIORITIZING │
│ │
│ Current Turn: Cost: $0.16000 | Tokens: 500 │
│ Prompt: 100 | Output: 50 | Thoughts: 350 │
│ │
│ Cumulative Burn: Cost Burn: [██████████████░░░░░░] 72.0% ($0.36000 / $0.50000) │
│ Token Burn: [█████████░░░░░░░░░░░] 44.8% (1120 / 2500) │
└────────────────────────────────────────────────────────────────────────────────────┘
Phase 3: Panicking (Budget used >= 80%)
[SAFETY INTERVENTION] Setting agent temperature = 0.0 to prevent token drift.
[SAFETY INTERVENTION] Restricting thinking/reasoning budget to 0 to conserve final cents.
┌────────────────────────────────────────────────────────────────────────────────────┐
│ Status: PANICKING │
│ │
│ Current Turn: Cost: $0.07000 | Tokens: 550 │
│ Prompt: 150 | Output: 120 | Thoughts: 280 │
│ │
│ Cumulative Burn: Cost Burn: [█████████████████░░░] 86.0% ($0.43000 / $0.50000) │
│ Token Burn: [█████████████░░░░░░░] 66.8% (1670 / 2500) │
└────────────────────────────────────────────────────────────────────────────────────┘
Agent outputs HTML landing page source.
┌────────────────────────────────────────────────────────────────────────────────────┐
│ Status: PANICKING │
│ │
│ Current Turn: Cost: $0.02000 | Tokens: 300 │
│ Prompt: 0 | Output: 250 | Thoughts: 50 │
│ │
│ Cumulative Burn: Cost Burn: [███████████████████░] 96.0% ($0.48000 / $0.50000) │
│ Token Burn: [█████████████████░░░] 86.8% (2170 / 2500) │
└────────────────────────────────────────────────────────────────────────────────────┘
Phase 4: Success - MVP Shipped safely under budget constraints!
┌────────────────────────────────────────────────────────────────────────────────────┐
│ Status: SHIPPED │
│ │
│ Current Turn: Cost: $0.01000 | Tokens: 80 │
│ Prompt: 50 | Output: 0 | Thoughts: 30 │
│ │
│ Cumulative Burn: Cost Burn: [████████████████████] 98.0% ($0.49000 / $0.50000) │
│ Token Burn: [██████████████████░░] 90.0% (2250 / 2500) │
└────────────────────────────────────────────────────────────────────────────────────┘
Scaling This to Production
While we built this monitor for a 50¢ mock startup demo, the core SRE architecture scales directly to real production:
- Multi-Tenant Escrows: In SaaS applications, you can assign a strict dollar limit to each customer API key. The monitor cuts off connections the instant their balance is depleted, protecting your primary account keys.
- Model Degradation Routing: When a budget warning is triggered, you can programmatically downgrade the connection from a premium reasoning model (like Gemini 3.5 Pro) to a fast utility model (like Gemini 3.5 Flash) to wrap up the execution cheaply.
- Context Compaction: Rather than bluntly discarding history turns, you can call a smaller background model to summarize the historic conversation logs on the fly, shrinking your prompt size while preserving the agent’s core memory.
Final Takeaways for AI Architects
If you’re deploying autonomous agents today, cost engineering isn’t an afterthought—it’s a core design constraint:
- Bind to Turn Boundaries: Don’t rely on retrospective logging. Bind monitoring logic to SDK turn boundaries so you can stop runs before they charge your card.
- Control Context Inflation: Keep a tight grip on history size to stop prompt costs from scaling quadratically.
- Always Build an Escrow: Treat token budgets as a finite runtime resource. Never deploy an agent without a hard session budget monitor.
Hope you enjoyed this piece; check out the entire code on GitHub 🎓
Huge thanks to the Google ML Developer team for organizing #AgenticArchitectSprint. Google Cloud credits are provided for this project✨ #BuildWithAI #BuildWithGemini #BuildWithGoogleAntigravity #BuildWithAntigravity #AISprint #GeminiSprint #AgenticArchitect #GoogleAntigravity
_